FIFA世界杯官方合作指定网站 拒却“出厂即巅峰”!具身考验系统再进化:LWD让机器东谈主自主开启“打怪练级”

智东西
作家 | 江宇
剪辑 | 漠影
刻下具身智能的发展,正卡在一个越来越明确的瓶颈上:数据领域与竟然天下训戒的不及。
夙昔几年,VLA等大模子让机器东谈主在“预考验阶段”取得了显耀进展,但一朝干预竟然部署环境,问题随之显露——面对复杂、多变的物理天下,模子才气很难抓续升迁,照旧高度依赖东谈主工标注数据和叠加考验。
这也意味着,具身智能尚未委果干预“领域化增长”的阶段。
仅依赖实践室数据或仿真环境,很难复旧机器东谈主才气的抓续演进;委果简略带来跃迁的,仍然是来自竟然天下、抓续积贮的高质料交互数据。但问题在于:这些数据从那边来?
现阶段,大批考验数据仍依赖东谈主工示教或遥操作收集,领域有限、本钱不菲,且难以障翳通达环境中的复杂长尾场景。
要让数据领域委果“滚动起来”,唯独可行的旅途,是让机器东谈主走出实践室,在竟然场景中永恒启动,并将交互训戒抓续回流。
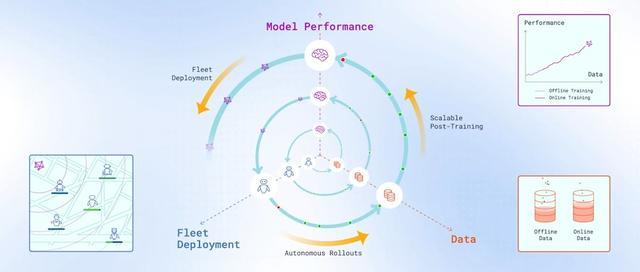
也恰是在这一布景下,上海创智学院和智元具身征询中心合资发布了最新服从罗剑岚团队建议LWD(Learning While Deploying)大领域强化学习考验系统。该职责由创智学院导师,智元首席科学家罗剑岚团队完成。尝试将“部署”本人转动为学习历程的一部分。
这项职责并不聚焦单一算法突破,更给出了一种更具工程可行性的有规画——通过在竟然天下中抓续启动机器东谈主,并将其行为数据长入回流与更新,让每一台机器东谈主既是任务奉行者,亦然抓续产生学习信号的数据源,从而鼓舞通用政策在部署历程中不绝进化。
一、让数据飞轮在物理天下自主决骤
传统效法学习范式下,非完好的启动轨迹不时被视为“废数据”平直丢弃,NBA下注(中国)官网入口机器东谈主只可从奏效的东谈主类演示中刻板地效法。
LWD的中枢颠覆在于,它构建了一个由竟然天下强化学习驱动的闭环数据飞轮。
在这个飞轮中,机器东谈主集群在竟然任务中自主奉行并积贮异构的交互训戒,无论是完好的奏效轨迹、试错后的自我收复、如故东谈主类为了障翳范畴情况而率领的失败案例,皆会被长入运输至云表的分享重放缓冲区。
强化学习机制使得这些在传统视角下的“失败”或“未必”数据,一起转动为了率领模子狡饰失误、优化价值评估的选藏训戒。
跟着集群部署领域的扩大和启动时辰的累积,数据飞轮的转速不绝升迁,云表抓续更新的强政策又会如期下发给机器东谈主,变成委果的自主造血闭环。
二、强化学习算法深层进化:在嘈杂数据中,精确捕捉“跳跃”信号
刚硬化学习讹诈于竟然天下部署的大领域机器东谈主集群,靠近着顶点的算法挑战。
不同机器东谈主在不同任务中产生的数据极其雄伟,包含着全皆不同的提醒、诟谇不一的操作历程,2026世界杯官网入口以及十分寥落的奖励响应。
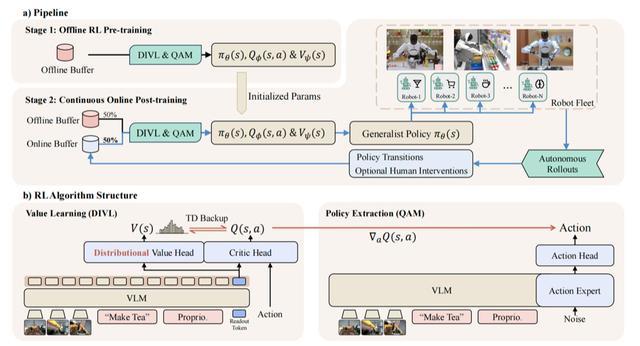
为了在这些充满噪声的“异质数据”中褂讪索取有用的学习信号,LWD改进性地引入了散布隐式价值学习(DIVL)算法。
通俗来说,以往的算法像是在给机器东谈主的发达打一个固定的“平平分”,但在复杂环境中这种打分极不准确;而DIVL则让机器东谈主学会去相关发达的“概率散布”,它不再只看一个点,而是不雅察总共这个词可能性的区间。
这让机器东谈主在很少得到明确奖励的情况下,也能精确判断哪些动气派险更高、哪些当作更值得尝试,从而有用处理了评价不准、容易过度乐不雅的老浩劫问题。
与此同期,针对VLA模子通过多步去噪产生当作的特色,传统的更新形势盘算推算量大且容易跑偏。
LWD合并了Q-learning with Adjoint Matching(QAM),为模子找到了一条数学上的“进化捷径”,让复杂的政策更新不再需要推倒重来,而是通过局部休养就能竣事快速迭代,保证了机器东谈主在大领域部署时的学习服从。
三、真金不怕火就“通才政策”:挑战5分钟长程复杂操作的极限奏服从
为了考据这套考验框架的实战发达,征询团队在智元G1双臂机器东谈主集群上进行了大领域的竟然天下部署测试。
测试涵盖了八项极具挑战性的多模态操作任务,包括四类考验语义识别与泛化的商超货架动态补货任务,以及泡功夫茶、榨果汁、调酒、装鞋入盒等四类长程连贯操作任务。

评测任务表现图。(A)调制鸡尾酒;(B)冲泡功夫茶;(C)制作果汁;(D)装鞋入盒;(E)商超补货。
在这些抓续时辰长达5到8分钟、包含数十个构兵丰富且存在长程依赖的物理交互任务中,LWD展现出了压倒性的上风。
各任务逐步奏服从的实践阻隔
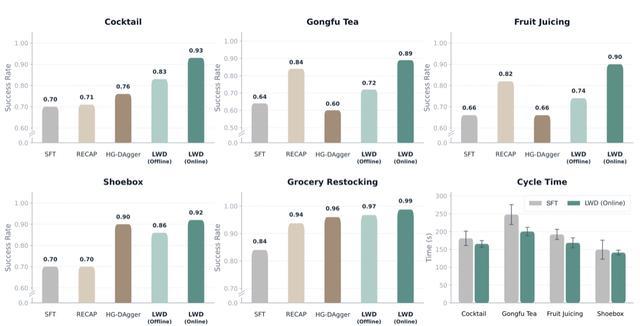
实践数据炫夸,经过在线竟然训戒积贮后,LWD考验出的单一通用政策在总共任务上的平均奏服从达到了惊东谈主的0.95,远超纯行为克隆(0.76)以及先进的离线强化学习基线如RECAP(0.86)和 Dagger-SOP(0.82)。

八项竟然天下操作任务的主要阻隔,涵盖四类商超补货任务和四类长程任务。阻隔炫夸,LWD(在线)取得了最高的全体平均收获,并在四项长程任务中一起取得最高分,同期在商超补货任务中也保抓在最优或接近最优水平。
调制鸡尾酒
尤其在最考验中间失误收复与永恒信用分派的长程任务中,LWD在线更新后的奏服从竣事了极大幅度的跃升,阐述了基于物理天下训戒的抓续学习是突破复杂操作天花板的有用旅途。
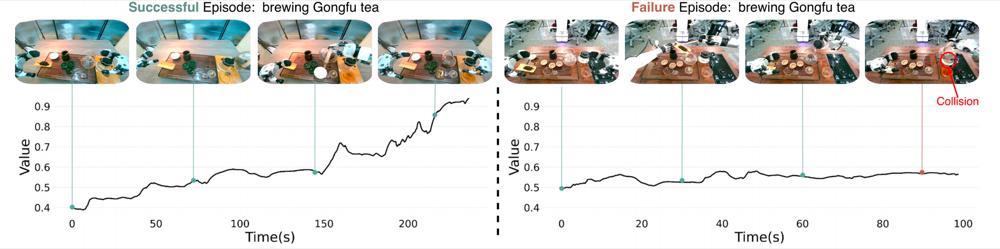
图中展示了功夫茶任务中一次奏效奉行(左)和一次失败奉行(右)的价值弧线。阻隔标明,所学习到的价值简略对任务完成程度提供有真理的表征。
结语:把“部署”变成才气增长滥觞,让机器东谈主在竟然天下抓续进化
在具身智能的产业化进程中,LWD鼓舞的不仅是算法框架的升级,更是机器东谈主才气迭代形势的一次紧要转向。
长久以来,业界民俗将“部署”视为模子考验的尽头,而LWD的建议阐述了,自主更正应当成为通用机器东谈主政策的基本属性。
学习不应是“出厂即封存的静态才气”,而必须成为部署之后在竟然天下里一直延续的进化历程。
只须赋予机器东谈主从海量无序的竟然物理交互中自主索取“营养”、抓续自我进化的才气,其才能委果冲破被东谈主工标注数据框定的适意区FIFA世界杯官方合作指定网站,在千行百业的复杂、通达场景中长久地开释交易价值。
金佰利app官网下载入口