2026FIFA世界杯中国官网 智谱公布“降智”的巧妙:Scaling不能幸免的痛

鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
Scaling即正义?智谱挠了挠头——
很磨折,而况压力山大……

智谱最新发布的一篇技能博客,画风略略有点不相似:
莫得当年的硬核技能输出,反而大倒苦水从GLM-5以来的多样项目踩坑,官方称之为「Scaling Pain」。
咱们的推理基础才略正承受着前所未有的压力,每天齐要工作数亿次Coding Agent调用。
当年几周,一些用户在使用GLM-5系列模子扩充复杂Coding Agent任务时,碰到多种特别,比如乱码、复读和罕有字符生成。
而况这些问题在圭臬推理环境中根柢复现不出来!!!

排查数周,团队终于揪出真凶,透顶刺破Scaling Laws路上的隐形Bug。
不仅详备回来了自身碰到的腾贵教养,还给出了一套极具实操性的避坑指南。
轻便来说,要是屏幕前的你正策动给我方的Agent加码,那么这篇来自一线实战的阅历回来,疏远先反复阅读背诵~

定位关节Bug
事情是酱紫的——
自从GLM-5发布以来,智谱通过不雅察用户的大限制Coding Agent推理过程,发现了三类特别时势:
乱码输出:本体杂沓无道理;
重复生成:模子不停重复输出调换本体;
冷漠字:出现特别字符。
这引起了团队工程师的警醒,于是说干就干,先是通过腹地回放用户响应,重复运行调换肯求数百次,限度永远无法触发特别。
换言之,模子自己并非根本原因。
在进一步模拟在线环境后,团队尝试弯曲PD鉴识比例并捏续提高系统负载,特别时势终于得以复现,在每10000个肯求中约莫能复现出3-5个特别输出。
这诠释,特别时势很有可能出自傲负载下的推理景色管束,指向底层推理链路。
但同期也引出了另一个问题,NBA下注(中国)官网入口线下的复现率仍低于用户线上响应的频率,这就意味着现存的检测要领存在遗漏或触发要求尚未十足秘密。
于是智谱团队链接对特别输出的检测要领进行优化。他们发现投契采样(Speculative Decoding)野心可当作特别检测的进军参考。
投契采样底本用于进步模子推感性能,它先由小模子生成草稿(draft tokens),再由大模子考证是否汲取这些token,最终大概在不编削输出分散的情况下进步decode后果。
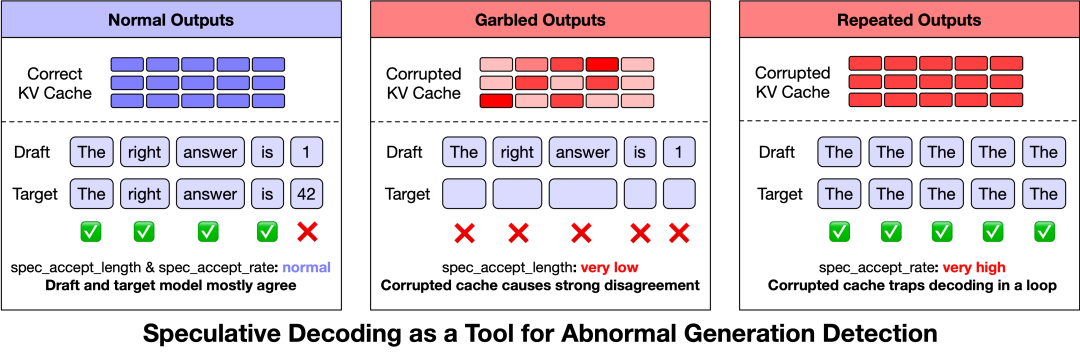
而在GLM-5的三类特别中,乱码和冷漠字的spec_accept_length格外低,也即是说标的模子的KV缓存景色与草稿模子之间存在彰着不匹配。
复读则领有过高的spec_accept_length,标明损坏的KV缓存可能导致闪耀力样式退化,将生成过程推向高置信度的重复轮回。
基于以上不雅察,智谱回来出了一套在线特别监控计谋:
当spec_accept_length捏续低于1.4且生成长度卓著128 token,或者spec_accept_rate卓著0.96,系统就会主动中止刻下生成,并将肯求再行交回给负载平衡器。
紧接着,FIFA世界杯官方合作指定网站智谱初始进一步领路特别原因:
PD鉴识架构下的KV Cache竞态
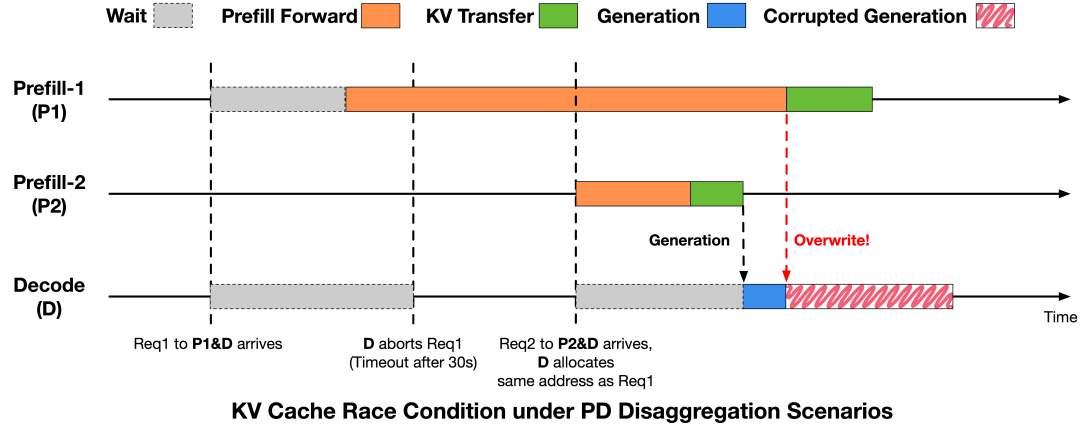
团队通过分析肯求生命周期和推理引擎中的PD鉴识扩充时序,将问题归因于肯求生命周期与KV Cache回收与复用时序之间的不一致,从而激勉的KV Cache复用壅塞。
为了摒弃这类竞态情况,考虑东谈主员在推理引擎中引入了更为严格的时序敛迹,会在肯求绝交和KV Cache写入完成之间建树显式同步。
具体来说,在发出中止提醒后,解码阶段会向预填充阶段发送见告。预填充阶段唯独在知足以下任一要求时才会复返安全回收信号:未启动任何RDMA写入,或通盘先前发出的写入操作已十足完成。而解码阶段唯独在收到此证据后才会回收并重用相应的 KV Cache槽位。
该机制将确保KV Cache写入不会逾越内存复用鸿沟,从而幸免跨肯求的KV Cache损坏。
最终斥地该bug后,特别输出的发生率从约万分之十几着落至万分之三以下。
HiCache加载时序缺失
此外,当KV Cache换入与运筹帷幄访佛期,刻下已毕未能保证数据在使用前已完成加载,导致可能出现未就绪KV Cache被看望的情况。
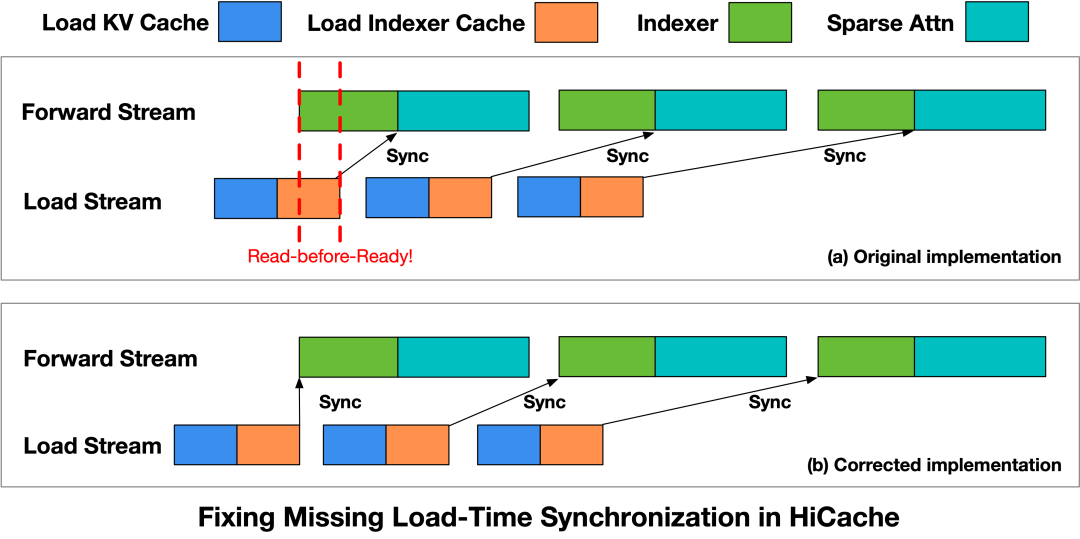
为惩处这一问题,团队重构了HiCache读取历程,同期引入数据加载与运筹帷幄之间的显式同步敛迹。
在启动Indexer算子之前,先插入一个Load Stream同步点,确保相应级别的Indexer缓存已十足加载。Forward Stream唯独在数据准备就绪后才会进行运筹帷幄,从而摒弃了read-before-ready的问题。
运用此斥地后,在调换的职责负载要求下,由扩充时序不一致引起的特别被摒弃,系统终于得以褂讪。
Prefill侧优化
事实上,这两种Bug齐指向了归拢个常见的系统瓶颈:
在长高下文的Coding Agent Serving任务中,Prefill阶段还是成为影响系统性能的主要要素。
于是为了缓解Prefill阶段在高并发下的内存和带宽压力,团队另外想象了KV Cache分层存储决议——LayerSplit。
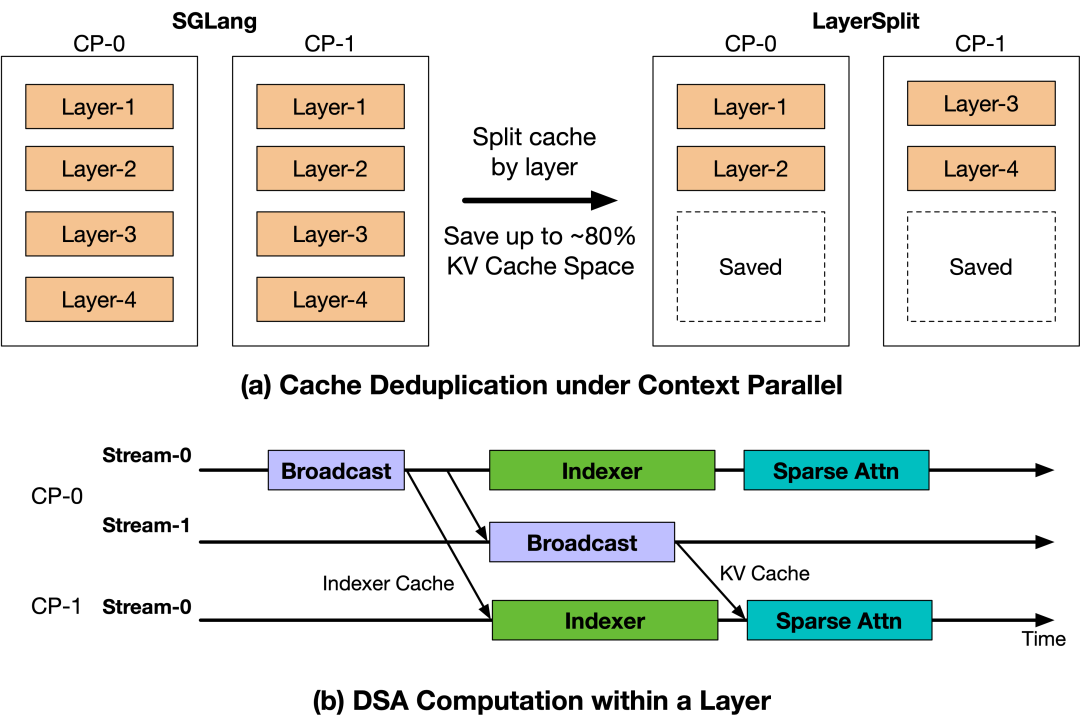
在该决议中,每个GPU只存储部分层的KV Cache,权臣缩小了每个GPU的内存占用。然后在扩充Attention运筹帷幄前,将对应层的KV Cache播送给其他谈判rank。
为了缩小通讯支出,还进一步想象有KV Cache播送与indexer运筹帷幄的访佛机制,将通讯延伸瞒哄在运筹帷幄过程中。这么独一的特别通讯支出就来自Indexer Cache的播送,其大小仅为KV Cache的八分之一,举座通讯资本不错忽略不计。
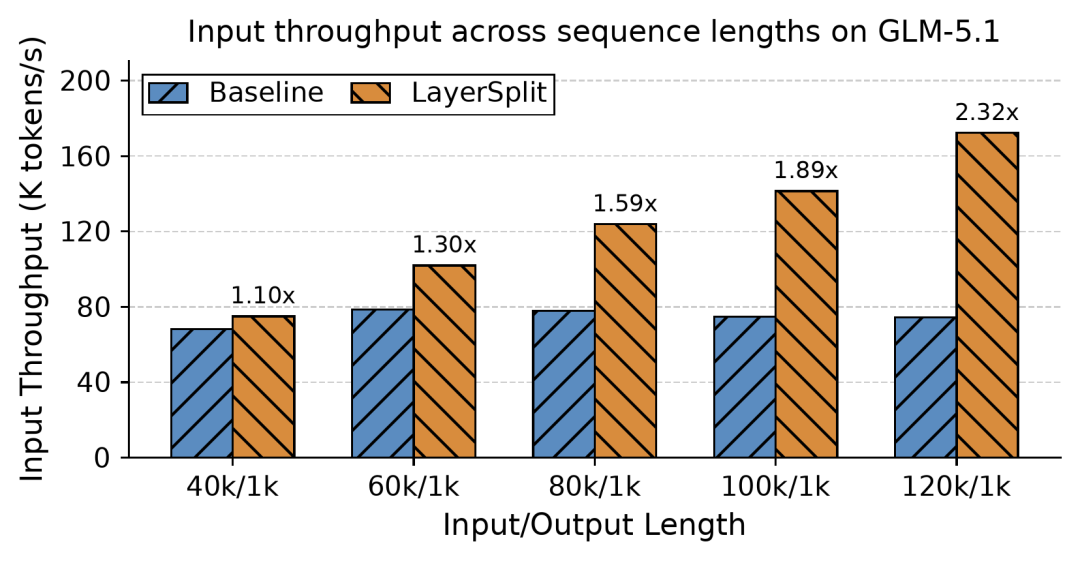
团队将LayerSplit和GLM-5.1聚积发现,在Cache掷中率达到90%、肯求长度在40k到120k区间内时,系统否认量提高了10%到132%,且跟着高下文长度的加多,收益也随之增长。
总体而言,该优化权臣进步了系统在Coding Agent场景下的处明智力。
同期智谱也合计2026FIFA世界杯中国官网,当智能真确插足高并发、长高下文的Coding Agent场景后,清静推理基础才略的输出质料变得至关进军。未来大限制AI需要的不仅是Scaling Law股东的智力增长,还必须有等量级的系统工程支捏。
金佰利app官网下载入口